言語処理学会にて『NLP2020 言語資源賞』を受賞
国立国語研究所コーパス開発センターの浅原正幸教授(A01班)、加藤祥研究員は、第26回言語処理学会年次大会にて、自然言語処理の事前学習モデルに基づく文脈化単語埋め込み情報付きデータを構築し、NLP2020 言語資源賞(言語資源協会・言語処理学会)を受賞しました。
https://www.gsk.or.jp/event/nlp2020-lra/
「BERTed-BCCWJ: 多層文脈化単語埋め込み情報を付与した『現代日本語書き言葉均衡コーパス』データ」
浅原正幸・加藤祥
言語処理学会第26回年次大会発表論文集 (2020年3月)
発表概要
単語埋め込みは、可変長離散系列である言語を数百次元の実ベクトル空間に写像する技術です。既存の単語埋め込み技術は語(タイプ)に対するベクトル表現でしたが、ELMo などに代表される文脈化単語埋め込みは語の出現(トークン)に対するベクトル表現をもたらします。また、 BERT と呼ばれる自然言語処理の事前学習モデルは、質問応答システムや自然言語推論(含意関係認識)などで既存手法を大幅に上回る性能を達成していますが、ELMoと同様に文脈化単語埋め込みを出力します。
A01班では、200億語・12億文を超える『国語研日本語ウェブコーパス (NWJC)』を用いて、『分類語彙表番号-UniDic語彙素番号対応表 (WLSP2UniDic』の語彙素に対応する形式で、言語研究向けの BERT である NWJC-BERT を今回新たに構築しました。このモデルを『現代日本語書き言葉均衡コーパス』に適用して、各単語に 768次元のベクトル情報を付与したものが BERTed-BCCWJです。
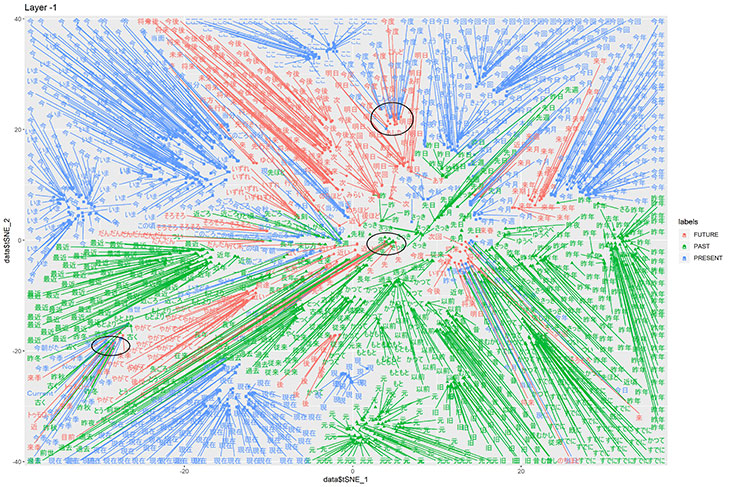
評価においては、『現代日本語書き言葉均衡コーパスに対する分類語彙表番号付与データ (BCCWJ-WLSP)』における現在(分類番号 .1641)・過去(同 .1642)・未来(同 .1643) を抽出したうえで、「今度」(図上部:現在 or 未来)や「先」(図中央:過去 or 未来)の多義性が識別できることを確認しました。また「USAトゥデー」や「トゥモローランド」といった時間性を帯びない固有表現が他の表現から区別されることも確認しました(図左下)。
今後、同データと脳活動データとを対照することで、現在・過去・未来のことを考えているときに脳のどの部分が活動するのかという調査を行います。
BERT (Github): https://github.com/google-research/bert
“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (arXiv): https://arxiv.org/abs/1810.04805
『国語研日本語ウェブコーパス』: https://pj.ninjal.ac.jp/corpus_center/nwjc/
『分類語彙表―増補改訂版データベース』: https://pj.ninjal.ac.jp/corpus_center/goihyo.html
『分類語彙表番号-UniDic語彙素番号対応表』(Github): https://github.com/masayu-a/WLSP2UniDic
「NWJC-BERT: 多義語に対するヒトと文脈化単語埋め込みの類似性判断の対照分析」: https://www.anlp.jp/nlp2020/program.html#B4-4
『現代日本語書き言葉均衡コーパス』:https://pj.ninjal.ac.jp/corpus_center/bccwj/
『現代日本語書き言葉均衡コーパスに対する分類語彙表番号付与データ』(Github): https://github.com/masayu-a/BCCWJ-WLSP
「BERTed-BCCWJ: 多層文脈化単語埋め込み情報を付与した『現代日本語書き言葉均衡コーパス』データ」: https://www.anlp.jp/nlp2020/program.html#P2-5