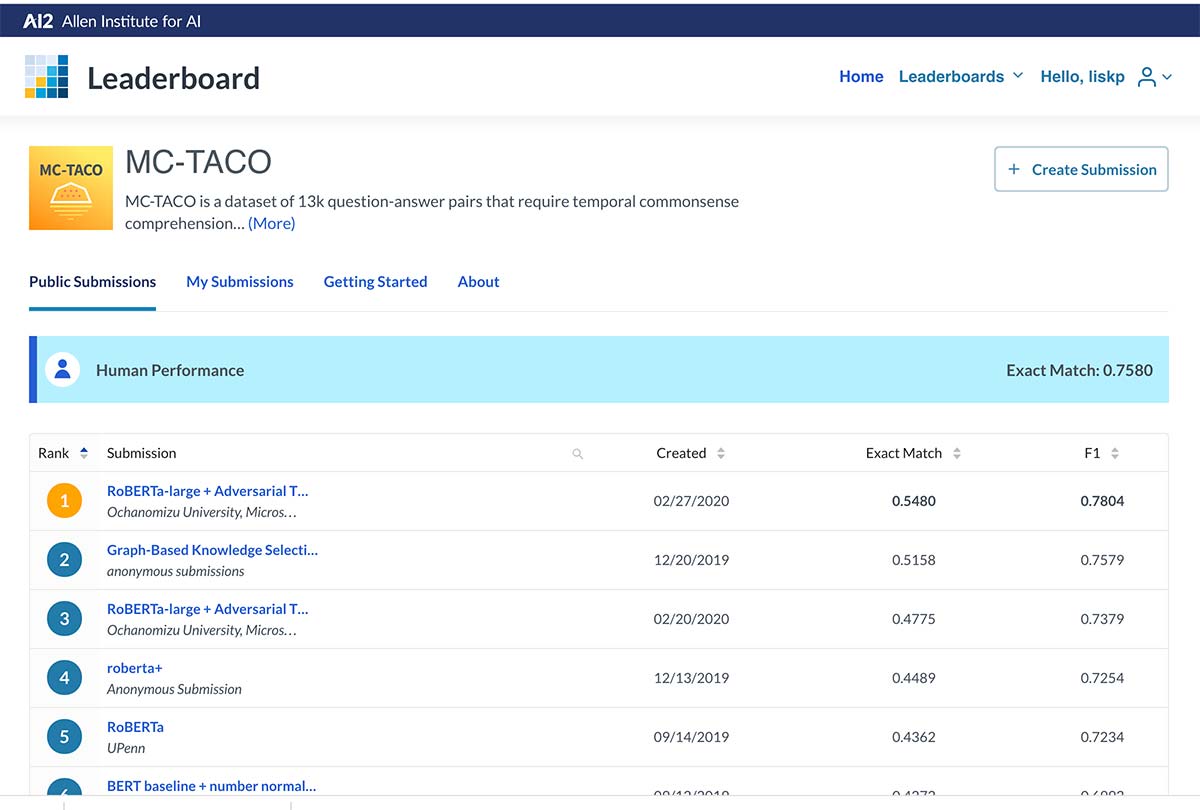
Dr. Lis Kanashiro Pereira and colleagues got the 1st place for the temporal commonsense comprehension task.
Temporal commonsense knowledge is often necessary to understand events expressed in natural language. This knowledge involves several temporal aspects of events, such as duration, frequency, and temporal order. This knowledge is still challenging for computers to understand.
Dr. Kanashiro and her colleagues built a deep neural network model to attempt to solve the problem. Their model got the 1st place on the official leaderboard for the temporal commonsense comprehension task.
Temporal commonsense knowledge is often necessary to understand events expressed in natural language. This knowledge involves several temporal aspects of events, such as duration, frequency, and temporal order. Most humans would know that, for example, an event such as “going on a vacation" takes longer and occurs less often than an event such as “going for a walk". However, it is still challenging for computers to understand and reason about temporal commonsense.
Recently, contextual pre-trained language models have advanced the state-of-the-art on various commonsense NLP tasks (Kocijan et al., 2019; He et al., 2019). In our work, we investigate the temporal commonsense ability of the contextual pre-trained language model RoBERTa (Liu et al., 2019). RoBERTa builds on BERT's language masking strategy (Devlin et al., 2019), and includes modifications such as hyperparameter tuning and training set size, and has been shown to generalize better to downstream tasks compared to BERT.
Inspired by the work of Jiang et al. (2019), we used an adversarial training approach to alleviate the overfitting and knowledge forgetting issues typically caused when fine-tuning large scale language models.
We evaluated our model on the MC-TACO dataset (Zhou et al. 2019). This dataset has 13k question-answer pairs that require temporal commonsense comprehension. On the official leaderboard for this task, we ranked first in terms of F1 and Exact Match scores. We confirm previous findings that a notable amount of commonsense knowledge can be acquired via pre-training contextual language models. However, our model is still far behind human performance, motivating further research in this area.
https://leaderboard.allenai.org/mctaco/submissions/public
As of February 27th, 2020.
Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT 2019, pages 4171–4186, Minneapolis, Minnesota, June 2 - June 7, 2019.
He, P., Liu, X., Chen, W., & Gao, J. A hybrid neural network model for commonsense reasoning. In Proceedings of the First Workshop on Commonsense Inference in Natural Language Processing, pages 13–21 Hongkong, China, November 3, 2019.
Jiang, H., He, P., Chen, W., Liu, X., Gao, J., & Zhao, T. SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. arXiv preprint arXiv:1911.03437, 2019.
Kocijan, V., Cretu, A. M., Camburu, O. M., Yordanov, Y., & Lukasiewicz, T. (2019). A surprisingly robust trick for winograd schema challenge. arXiv preprint arXiv:1905.06290.
Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., ... & Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
Zhou, B., Khashabi, D., Ning, Q., & Roth, D. " Going on a vacation" takes longer than" Going for a walk": A Study of Temporal Commonsense Understanding. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3363–3369, Hong Kong, China, November 3–7, 2019.
Lis Kanashiro Pereira (Ochanomizu University), Xiaodong Liu (Microsoft Research), Fei Cheng (Kyoto University), Masayuki Asahara (The National Institute for Japanese Language and Linguistics) and Ichiro Kobayashi (Ochanomizu University).